こんにちは。情熱開発部プログラム課の安田です。
Visual Studioはじめ、各種C++コンパイラのC++20対応が着々と進む中、CEDEC2020でC++20の機能を紹介する講演が実施されるなど、ゲーム業界でもC++20導入の機運が高まっています。今回はC++20の新機能の中でも、個人的に特に気になっていた「モジュール」について紹介します。
- 1. C++20のモジュールとは?
- 2. C++のビルドの仕組み
- 3. 複数ファイルからなるプログラムのビルド
- 4. #includeを使う上での注意点
- 5. 改めてモジュールの利点を考えてみる
- 6. モジュールを試してみる
- 7. おわりに
- 参考資料
目次
1. C++20のモジュールとは?
モジュールとは、C++20で新たに導入される、 インクルードに代わる新たなプログラム分割の仕組みのことです。
cpprefjpによると、C++にモジュールが必要になったのは、以下のような背景があるようです。
プリプロセッサによるインクルードは、ヘッダーファイルの内容をその場に展開する。 これには次のような問題が指摘されてきた。
1. コンパイル時間が長くなる
ヘッダーファイルの内容が再帰的に展開され、プログラムが長くなる(Hello worldだけでも数万行に達する)
さらに、展開が翻訳単位ごとに行われるので、全体で見ると同じヘッダーファイルが何度も解析される
2. プリプロセッサの状態により、インクルードの結果が変わってしまう
インクルードの順番によってエラーが起きることがあった。
3. ヘッダーファイル内の記述の影響を受けすぎる
影響が大きいため、ヘッダーファイル内に書くことがためらわれる記述があった。
using namespaceやマクロ(例えばWindowsにおけるmax)など。モジュールは、以上のような問題のないプログラム分割の仕組みとして導入された。
https://cpprefjp.github.io/lang/cpp20/modules.html
専門用語が多くて難しい……
しかし、モジュールの利点を正しく把握していなければ、慣れ親しんだインクルードを捨てて、わざわざモジュールに移行しようという気にはなれません。
というわけでここから基本に立ち返って、ビルドの手順を振り返りながら、旧来のインクルード(#include)が実際に何をしているのか詳しくみていきます。その後、改めてモジュールの利点について考えてみます。
2. C++のビルドの仕組み
インクルードの挙動を理解するには、C++のビルドの仕組みについて把握していなければなりません。ここでいうビルドとは、C++のソースコードを、実行ファイルやライブラリに変換する処理のことを指します。
ここではビルドの処理について、下図を元に説明します。なお、これらの説明はこちらのサイトを参考に記述しています。

ビルドは、プリプロセッサ、コンパイラ、アセンブラ、リンカという4つの手続きからなります。
2.1. プリプロセッサ
プリプロセッサ(preprocessor, Cプリプロセッサとも)とは、ソースコードをアセンブラに変換する前に、テキストを変形する前処理のことです。プリプロセッサは主に以下の処理を実行します。
- コメントを削除する
#から始まるプリプロセッシングディレクティブ(preprocessing directive)を処理する
プリプロセッシングディレクティブには #includeや#defineなどがあります。#includeとはプリプロセッシングディレクティブの一つだったのです。#includeディレクティブは、指定したファイルの中身をその場に展開します。ようはそのファイルの中身をコピペしているだけです。
#defineディレクティブは、トークンを別のトークンに置換する役割を持ちます。例えば #define INF 100000000 と記述した時、それ以降の行で「INF」という文字が現れれば、それは全て「100000000」に置き換わります。
2.2. コンパイラ
プリプロセッサで前処理を施したソースファイルは、一つずつコンパイラに渡され、コンパイルされます。コンパイルにより、ソースファイルはアセンブリに変換されます。アセンブリとは、機械語を人間が理解しやすい形に書き下した、低水準プログラミング言語です。
なお「コンパイル」という言葉は、プリプロセッサからリンクまでの処理を指すことがあります。ですがここでは、プリプロセッサからリンクまでの一連の処理のことを「ビルド」、コンパイラが実行する処理のことを「コンパイル」と区別して呼ぶこととします。
2.3. アセンブラ
アセンブラは、コンパイラが生成したアセンブリファイルを、マシンが解読できる形、つまり機械語に翻訳する役割を持っています。C++では、アセンブラが生成する機械語ファイルのことをオブジェクトファイルとも呼びます。オブジェクトファイルはバイナリ(2進数)、つまり0と1だけで表現された命令の羅列であり、コンピュータはこの命令に従って動作します。
2.4. リンカ
リンカは、作成された複数のオブジェクトファイルを一つにまとめる役割を持ちます。この図の例では、一つのソースファイル(main.cpp)でプログラムが完結しているので、リンカは特に何もしません。
リンカの処理が終わると、晴れてビルドが完了し、実行可能なファイルが生成されます。
3. 複数ファイルからなるプログラムのビルド
#includeはプリプロセッサを使ってプログラムを複数ファイルに分割するための仕組みです。では、実際に複数ファイルからなるプログラムをビルドして、プリプロセッサ、コンパイラなどの挙動を確認してみます。今回ビルドするプログラムは以下の3つのファイルからなります。
int add(int a, int b);#include "sample.hpp"
int add(int a, int b) {
return a + b;
}#include "sample.hpp"
int main() {
int n = 10, m = 20;
int result = add(n, m);
return 0;
}検証には、Windows Subsystem for Linux 2のUbuntu20.04 LTS上で動作するgccコンパイラを使いました。
3.1. ビルドの流れ
前章と同様に、このプログラムのビルドの流れを図示してみました。

3.2 プリプロセッサ
本来、プリプロセッサ処理はコンパイル時に暗黙的に実行されます。ですがg++の -E オプションで、プリプロセッサによる処理を終えた後のソースファイルを確認できます。
> g++ -E sample.cpp
# 1 "sample.cpp"
# 1 "<built-in>"
# 1 "<command-line>"
# 1 "/usr/include/stdc-predef.h" 1 3 4
# 1 "<command-line>" 2
# 1 "sample.cpp"
# 1 "sample.hpp" 1
int add(int a, int b);
# 2 "sample.cpp" 2
int add(int a, int b)
{
return a + b;
}
> g++ -E main.cpp
# 1 "main.cpp"
# 1 "<built-in>"
# 1 "<command-line>"
# 1 "/usr/include/stdc-predef.h" 1 3 4
# 1 "<command-line>" 2
# 1 "main.cpp"
# 1 "sample.hpp" 1
int add(int a, int b);
# 2 "main.cpp" 2
int main()
{
int n = 10, m = 20;
int result = add(n, m);
return 0;
}#から始まる行を無視すると、 #include “sample.hpp” と記述した行に、sample.hppの中身がそのまま展開されているのが分かります。
3.3. コンパイラ
コンパイラは、プリプロセッサが処理した1つのソースファイルを、1つの翻訳単位として扱いコンパイルします。つまりコンパイラは、sample.cppとmain.cppを別々にコンパイルします。
g++の -S オプションで、コンパイラが出力するアセンブラを確認できます。
> g++ -S sample.cpp -o sample.asm
> g++ -S main.cpp -o main.asm
> cat sample.asm
.file "sample.cpp"
.text
.globl _Z3addii
.type _Z3addii, @function
_Z3addii:
(以下省略)
> cat main.asm
.file "main.cpp"
.text
.globl main
.type main, @function
main:
(以下省略)ここで、改めてプリプロセッサが処理したmain.cppの中身(#から始まる行は無視)を見てみます。
int add(int a, int b);
int main()
{
int n = 10, m = 20;
int result = add(n, m);
return 0;
}この時点でmain.cppからは、add関数の中身の実装が見えないので、普通ならadd関数を使用する時点でエラーが出るはずです。にも関わらずコンパイルに成功します。
これは、コンパイラがadd関数について「int型の引数を2つ取るaddという名前の関数がある」という情報さえあれば、その中身は後で解決すればよいとしているからです。この情報の事をシンボルと呼びます。
C++コンパイラは関数が宣言されると、それに対応するシンボルを生成します。もし同じシンボルが生成されると、コンパイルは通りません。C++では、シンボルだけ生成され、対応する関数の実装がまだ決まっていない状態のことを、外部シンボル(参照)が未解決であるといいます。
3.4 アセンブラ
アセンブラは、コンパイラが生成したアセンブラファイルを解釈して、オブジェクトファイルを生成します。g++の -c オプションで、渡したソースファイルをオブジェクトファイルに変換できます。
> g++ -c sample.cpp -o sample.o
> g++ -c main.cpp -o main.o なおLinuxでは、nmコマンドを使って、オブジェクトファイル中に埋め込まれたシンボルを取得することが出来ます。
> nm -C sample.o
0000000000000000 T add(int, int)
> nm -C main.o
U _GLOBAL_OFFSET_TABLE_
U add(int, int)
0000000000000000 T main nm -C main.oの出力を見ると、add関数がU(未定義、Undefined)状態であることがわかります。
ちなみにC言語のコンパイラは、シンボルに関数名の情報しか載せません。そのためC言語には関数オーバーロードがないのです。一方C++コンパイラは、シンボルに関数名に加えて、「返り値の型」と「引数の型」の情報も載せます。この処理のことを名前マングリングと呼ぶそうです。C++は名前マングリングによって関数のオーバーロードを実現しています。
3.5 リンカ
リンカでは、アセンブラが生成した2つのオブジェクトファイルを束ねて、一つの実行可能ファイルを生成します。リンク後も、外部シンボルが未解決状態のもの、すなわち宣言はあるのに実装がないものがあれば、この時点でエラーになります。
> g++ -o program main.o sample.o
> ./program
# 特に何も出力されないが実行可能なことが確認できた3.6. (補足)外部ライブラリとの連携
外部ライブラリを使用したい時、そのライブラリのソースコードが全て公開されていれば、今回示した手順で正しくビルドできます。しかし、常に全てのソースコードが公開されるわけではありません。
ライブラリ製作者が作成したオブジェクトファイル(とヘッダ)があればそれを自分が書いたコードにリンクすることで、外部ライブラリを使用できます。
外部ライブラリを使用するこの仕組みは、オブジェクトファイルをリンクするタイミングによって、静的リンク・動的リンクと呼び分けられます。この辺りの詳しい解説は、#includeの解説とはかけ離れるため、今回参考にさせていただいたこちらのサイト に譲ります。
4. #includeを使う上での注意点
ここまでC++のビルドの手順について説明しました。再度の説明になりますが、#includeは指定したファイルの中身をその場に展開(コピペ)しているだけです。つまり、やろうと思えば下のような書き方だって出来ます。
// data.csv
10, 20, 30, 40, 50
// main.cpp
#include <iostream>
#include <vector>
int main()
{
std::vector<int> vec{
#include "data.csv"
};
for (const auto i : vec)
std::cout << i << ",";
return 0;
}ここから、私が知る限りの#includeを使用上の注意点を紹介します。
4.1. #include<>と#include””の違い
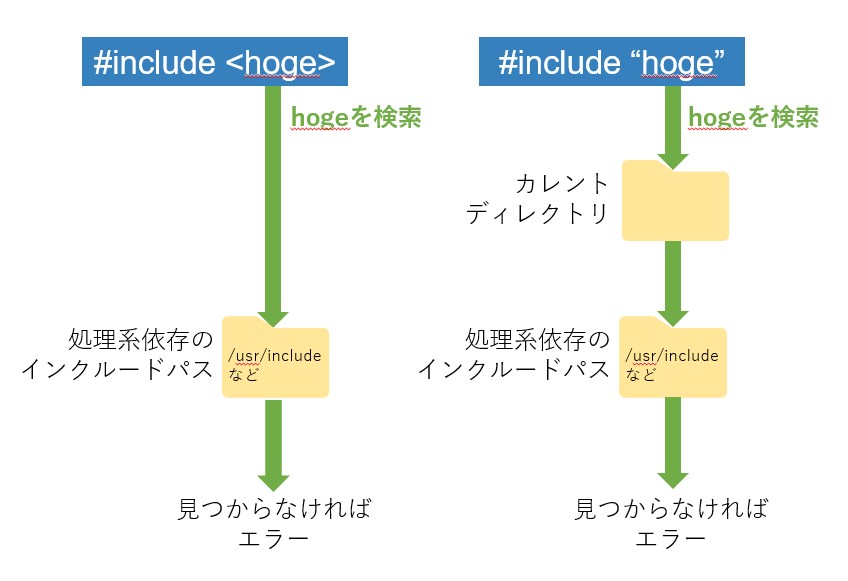
#include<hoge>と#include”hoge”は、どのディレクトリを検索するかで違いがあります。
#include<hoge>は、処理系指定のインクルードパスからのみファイルを検索します。一方#include”hoge”は、(一般的には)まずカレントディレクトリから対象のファイルがないか検索し、もし見つからなければ、処理系指定のインクルードパスを検索します。
#include <iostream> // OK
#include "iostream" // OK
#include "sample.hpp" // このファイルと同じディレクトリにsample.hppがあればOK
#include "./include/math/add.hpp" // このファイルから見て./include/math以下にadd.hppがあればOK g++では、-Iオプションでインクルードパスを追加できます。
> ls
main.cpp
> cat ~/test/print.hpp
#include <iostream>
void print() { std::cout << "Hello world!\n"; }
> cat main.cpp
#include <print.hpp>
int main() {
print();
return 0;
}
# ~/testをインクルードパスに追加してコンパイル
> g++ main.cpp -I ~/test
> ./a.out
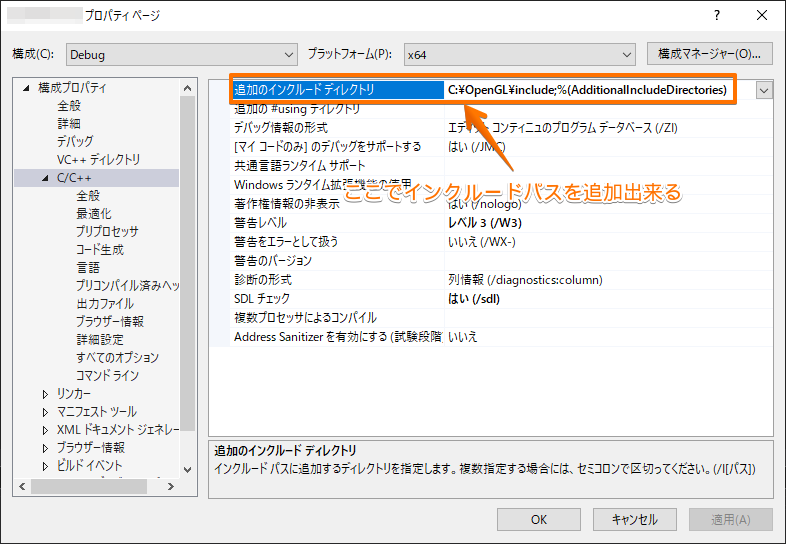
Hello world!Visual Studioの場合は、 .vcxproj ファイルを編集すればインクルードパスを追加できます。GUIから追加したい時は、 プロパティの構成プロパティ→ C++ → 全般 の「追加のインクルードディレクトリ」を編集します。
4.2. インクルードガード
C++では同じ翻訳単位に、同じ名前の関数及び変数を複数回定義することは禁止されています(これをODR(One Definition Rule、単一定義原則)と呼ぶ)。つまり下のようなコードは void f() が複数回定義されているため、コンパイルに失敗します。
// これは関数宣言
void f();
// 複数回宣言してもOK
void f();
// f()の関数定義
void f() {}
// 2回以上のf()の定義はNG
void f() {}C++では、慣例的にヘッダファイルで関数(クラス)を宣言し、ソースファイルでそれをインクルードして実装するというスタイルが取られます。
// print()の宣言
void print();
// sample.cpp
#include "sample.hpp"
#include <iostream>
void print() { std::cout << "Hello, world!\n"; }しかし、わざわざファイルを分けて定義するのが面倒な関数は、ヘッダファイルに関数の実装を書くことがあります。他にもclassや変数をヘッダファイル内で定義した時、そのヘッダファイルを複数回インクルードするとODR違反と見なされ、コンパイルが通りません
// sample.hpp
void f() {}
class A {};
// main.cpp
#include "sample.hpp"
#include "sample.hpp"
int main() {
return 0;
}> g++ main.cpp
In file included from main.cpp:2:
sample.hpp:1:6: error: redefinition of ‘void f()’
1 | void f() {}
| ^
In file included from main.cpp:1:
sample.hpp:1:6: note: ‘void f()’ previously defined here
1 | void f() {}
| ^
In file included from main.cpp:2:
sample.hpp:2:7: error: redefinition of ‘class A’
2 | class A {};
| ^
In file included from main.cpp:1:
sample.hpp:2:7: note: previous definition of ‘class A’
2 | class A {};
| ^この問題に対応するために、C++にはインクルードガードの仕組みがあります。
#ifndef INCLUDE_GUARD_HEADER_SAMPLE
#define INCLUDE_GUARD_HEADER_SAMPLE
void f() {}
class A {};
#endifこう記述したヘッダファイルは、2回目以降のインクルードがプリプロセッサ上で無視され、コンパイル対象にならないので、エラーが出なくなります。
# 試しにインクルードガードを施したsample.hppを2度インクルードした
# main.cppに対するプリプロセッサの出力を見てみる
> g++ -E main.cpp
void f() {}
class A {};
int main()
{
return 0;
}なおC++の言語標準ではありませんが、インクルードガードの代わりに #pragma once を使って、2重インクルードを避ける方法もあります。
// このファイルを複数回インクルードしてもエラーは出ない
#pragma once
void f() {}
class A {};今どきのコンパイラは、殆どが #pragma once に対応しています。
wikipedia(En) – pragma once
4.3. コンパイル時間が長くなりがち
#includeの多用は、コンパイル時間の肥大化に繋がります。
ここまで何度も述べたとおり、プリプロセッサによるインクルードはヘッダファイルの中身をその場に展開します。ということは、単なるHello worldだけでも、長大な<iostream>ヘッダをその場に展開するため、プログラムが長くなってしまいます。
> cat main.cpp
#include <iostream>
int main()
{
std::cout << "Hello, world\n";
}
> g++ -E main.cpp > post_main.cpp # プリプロセス後のmain.cppの中身をpost_main.cppに出力
> wc -l post_main.cpp # post_main.cppの行数をカウント
28629 post_main.cpp4.4. インクルードされるヘッダファイルに書くべきでない記述がある
インクルードされるヘッダファイルにusing指令やusing宣言を書くと予期せぬ名前衝突が起こり危険です。特に using namespace stdは避けるべきです。
// sample.hpp
#include <string>
using std::string; // std::stringがstd::をつけなくても使用できる
string make_message() { return "Hello, world!\n"; }
// myString.hpp
#include "sample.hpp"
class string { // std::stringと名前衝突しコンパイルエラー
};どうしてもヘッダファイル内でusing指令やusing宣言を使いたい時はブロックスコープ内で使用すると良いでしょう。
// sample.hpp
#include <string>
namespace sample {
using std::string; // std::stringがstd::をつけなくても使用できる
string make_message() { return "Hello, world!\n"; }
}
// myString.hpp
#include "sample.hpp"
class string { // using std::stringは別スコープにあるのでOK
};同様に、不要な名前衝突を避けるために、必要なければヘッダファイル内でマクロを使うのも極力避けるべきです。
4.5. インクルード順を変えるとエラーが発生することがある
ごく稀にインクルード順を変えるとエラーが発生することがあります。これもプリプロセッサでインクルードするヘッダファイルの中身をそのまま展開する故の問題です。以下にその簡単な例を示します。
// hoge.hpp
int hoge(int num)
{
int a = 10;
return num + a;
}
// fuga.hpp
#define a 100
int fuga(int num)
{
return num + a;
}
// main.cpp
#include "hoge.hpp"
#include "fuga.hpp"
#include <iostream>
int main()
{
std::cout << hoge(1) << ", " << fuga(1) << std::endl;
}hoge.hpp、fuga.hppの順でインクルードするとmain.cppのコンパイルは通ります。ですが、fuga.hpp、hoge.hppの順でインクルードするとmain.cppのコンパイルに失敗します。
#include "fuga.hpp"
#include "hoge.hpp"
// 以下略> g++ main.cpp
In file included from main.cpp:1:
hoge.hpp: In function ‘int hoge(int)’:
fuga.hpp:1:11: error: expected unqualified-id before numeric constant
1 | #define a 100
| ^~~
hoge.hpp:3:9: note: in expansion of macro ‘a’
3 | int a = 10;
| ^5. 改めてモジュールの利点を考えてみる
5.1. モジュールの利点
4章では#includeを使う上で知っておきたいこと、そしてその問題点について述べました。ここまで理解できると、C++20のモジュールの利点が何となく見えてきます。もう一度cpprefjp記載の「モジュールが必要になった背景・経緯」を見てみましょう。
1. コンパイル時間が長くなる
https://cpprefjp.github.io/lang/cpp20/modules.html
ヘッダーファイルの内容が再帰的に展開され、プログラムが長くなる(Hello worldだけでも数万行に達する)
さらに、展開が翻訳単位ごとに行われるので、全体で見ると同じヘッダーファイルが何度も解析される
2. プリプロセッサの状態により、インクルードの結果が変わってしまう
インクルードの順番によってエラーが起きることがあった。
3. ヘッダーファイル内の記述の影響を受けすぎる
影響が大きいため、ヘッダーファイル内に書くことがためらわれる記述があった。
using namespaceやマクロ(例えばWindowsにおけるmax)など。
モジュールはプリプロセッサを使わずにプログラムを分割出来ます。つまりモジュールは、#includeのようにプリプロセッサでヘッダを展開して依存関係を解決するのではなく、コンパイル時に自動で依存関係を解決してくれるのです。これにより#includeの問題は以下のように解消されます。
- コンパイル時間が長くなる
翻訳単位ごとにヘッダファイルを展開しないので、語句解析が早くなる。その結果、一般的にモジュールを使ったほうがコンパイル時間が短くなる。 - プリプロセッサの状態によりインクルードの結果が変わってしまう
- ヘッダーファイル内の記述の影響を受けすぎる
モジュールに記述したusing namespaceやマクロが、そのモジュールを使用するソースファイルに漏れなくなる。これにより、プリプロセッサの処理を追わないと容易に発見できなかったバグが発生しなくなる。
5.2. モジュールの欠点
先程モジュールは#includeと比べてコンパイル時間が短くなると話しましたが、逆にモジュールのほうが#includeよりコンパイル時間が長くなる場合があるようです。P1441R1 では、モジュールと#includeのベンチマーク計測結果が報告されています。以下に、P1441R1中で示されたモジュールと#includeのベンチマーク計測結果を比較したグラフを示します。


グラフ1を見ると、ジョブ数(並列数)が少ない時、モジュールは常に#includeよりも短い時間(最速で#includeの1/4の時間)でビルドできることが分かります。一方グラフ2では、ジョブ数(並列数)が64と大きい時、モジュールは依存関係が複雑になると、#includeよりビルドに時間がかかることが示されています。
並列数を増やすと逆にパフォーマンスが劣化するというモジュールの特性は、モジュールが依存順にコンパイルしなければならず、並列化しにくいことに由来します。ただ、並列数がそこまで多くない一般的なPCでビルドする分には、モジュールのほうが早いと考えていいと思われます。
5.3. #includeとモジュールの比較まとめ
以下に、ここまで示してきた#includeとモジュールの差異を表にまとめました。
| 比較点 | #include | モジュール |
|---|---|---|
| 互換性 | C / C++のどのバージョンでも利用可能 | C++20以降のみで利用可能 |
| ビルド時間 | 遅い | (基本的には)#includeより早くなる |
| 依存関係を解決するタイミング | プリプロセス時に、指定したファイルをその場に展開する | コンパイル時に、モジュール依存順に解決する |
| マクロやusing namespaceなど | #includeしたファイルに漏れるため、名前衝突が起こる恐れがある | マクロやusing namespaceなどは、モジュールの利用者からは見えない |
6. モジュールを試してみる
ようやくモジュールの利点について分かったところで、実際にモジュールを使ってみました。今回実装に使用したのは、2020年11月現在最もモジュールの実装が進んでいると言われるVisual Studio 2019のPreview版を使用しました。
6.1. 環境
Visual Studio 2019 Preview 16.8.0 Preview 6.0
6.2. 実装
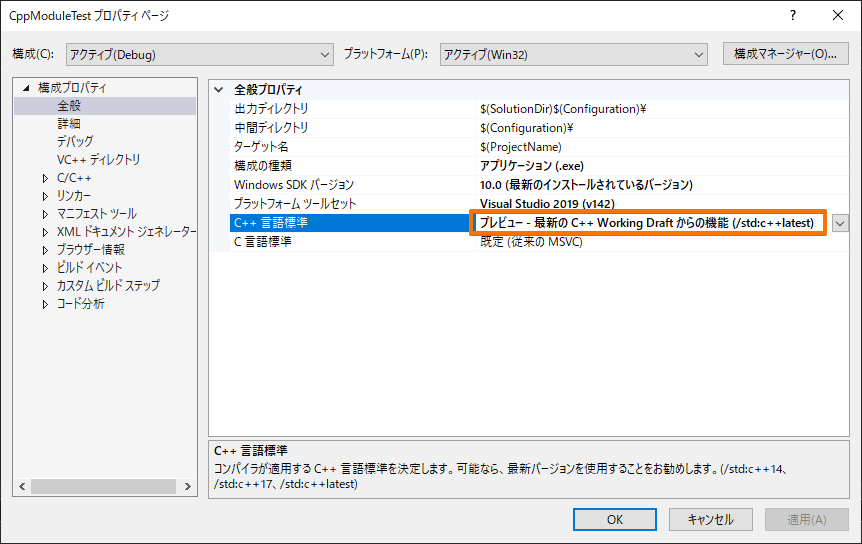
C++プロジェクトを作成したら、モジュールが使えるように、オプションからC++の言語標準をC++14からプレビュー(/std:c++latest)に変更してください。
モジュールを作成する時は、新しい項目の追加から「C++モジュールインターフェイスユニット(*.ixx)」を選択してください。
以下にモジュールを使ったコードの例を示します。なお、ここではモジュールの細かい文法については述べません。cpprefjpやMicrosoft C++ Team Blogの記事など既存の資料をご確認ください。
module;
#include <iostream> // #includeディレクティブはグローバルモジュールフラグメント内に記述する
#include <string>
// Printerモジュールを宣言
export module Printer;
// Printerモジュール中にPrinter構造体を定義、エクスポート
export struct Printer {
void operator()(const std::string& msg) const {
std::cout << msg << '\n';
}
};
// Prinerモジュール中にTwicePrinter構造体を定義、エクスポート
export struct TwicePrinter {
void operator()(const std::string& msg) const {
std::cout << msg << msg << '\n';
}
};import Printer; // Printerモジュールを取り込む
#include <string>
int main() {
Printer{}("Hello");
TwicePrinter{}("Hello");
return 0;
}
// 実行結果
// Hello
// HelloHello6.3. 補足
実際にVisual Studioでモジュールを使ってみたところ、まだ実用するのは厳しいかなと感じました。まずInteliSenceが言うことをきかず、暫く待たないとモジュールを認識しないということがままありました。また、まだ#includeと共存せざるを得ないので、その取り扱いにも苦労しました(なお今回は試していませんが、C++23以降でSTLのモジュール化が検討されているようです)。
加えて、C++で使われるC言語に対応したヘッダファイルは、今後もモジュール化されることはないと考えられます。モジュールには後方互換性のための機能がいくつか用意されていますが、今後全てをモジュールで記述できるようになるのは難しいのではと思われます。
7. おわりに
長くなりましたが、今回はC++20で導入されるモジュールについて、詳しく説明させていただきました。最初は「Visual Studioでモジュールを使ってみた」で終わるつもりだったのですが、気づいたらビルドの手順まで説明することになってしまいました。ですが、これまでIDEに任せきりで裏で実際に何をやっているのかよく分かっていなかった、ビルドの流れについて学べて非常に勉強になりました。
モジュールの他にも様々な便利機能が追加されているC++20。C++erの方は是非使ってみてください。
参考資料
ゲーム開発者のためのC++11~C++20,将来のC++の展望【Speaker Deck】https://speakerdeck.com/cpp/cedec2020
モジュール – cpprefjp C++日本語リファレンス https://cpprefjp.github.io/lang/cpp20/modules.html
C/C++のビルドの仕組みとライブラリ – かみのメモ https://kamino.hatenablog.com/entry/c%2B%2B-principle-of-build-library
C++20 モジュールの概要 / Introduction to C++ modules (part 1) https://www.slideshare.net/TetsuroMatsumura/c20-152189285
A Tour of C++ Modules in Visual Studio | C++ Team Blog https://devblogs.microsoft.com/cppblog/a-tour-of-cpp-modules-in-visual-studio/
#defineが関係するコンパイルエラーの原因を突き止める – Qiita https://qiita.com/Nekonecode/items/deb32c0218a906195648
結局C++でヘッダファイルはどう作るのがいいのか | teratail https://teratail.com/questions/196481
江添亮のC++入門 https://ezoeryou.github.io/cpp-intro/#include%E3%83%87%E3%82%A3%E3%83%AC%E3%82%AF%E3%83%86%E3%82%A3%E3%83%96
C++ tips1 #include編 https://www.slideshare.net/wraith13/cxx-tips1-include
【免責事項】
本サイトでの情報を利用することによる損害等に対し、株式会社ロジカルビートは一切の責任を負いません。

